Python获取网页指定内容(BeautifulSoup工具的使用方法)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址所对应的源代码,urllib2是需要用到的包,以上三句代码就能获得网页的整个源代码
2 获取网页中想要的内容(先要获得网页源代码,再分析网页源代码,找所对应的标签,然后提取出标签中的内容)
2.1 以豆瓣电影排名为例子
网址是http://movie.douban.com/top250?format=text,进入网址后就出现如下的图
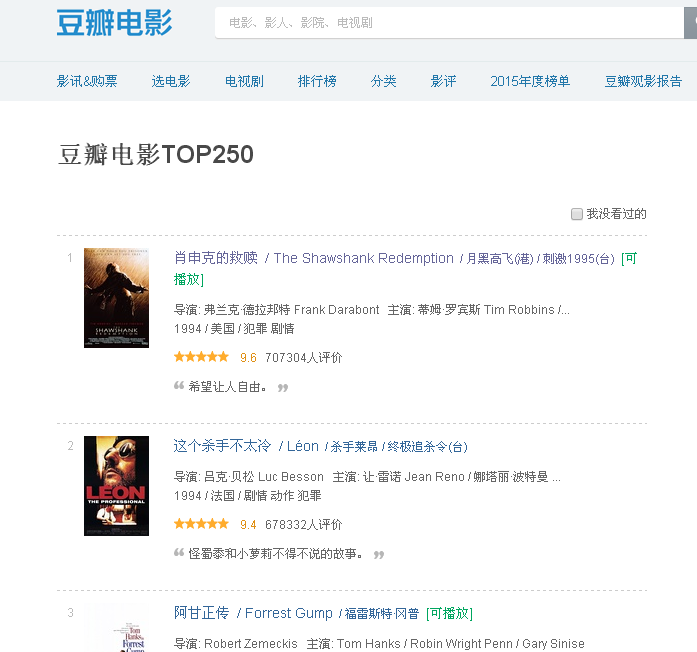
然后查看源码,找到对应的内容:(直接按f12)
就得到下面这张图:
然后划出重点

然后开始编写代码:
#coding:utf-8
'''''
@author: 徐松伟
'''
import urllib.request
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib.request.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "
" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
遇到的问题:
安装相关的库文件,会遇到反爬取 。就是说不能一直爬取 。代码经过多次运行以后就会触动该网站的反爬取。
现在python3.X以后urllib2和urllib合并了 所以导入的时候用 import urllib.request 有什么说的不对的地方请评论指出。