python——scrapy中Request参数
原文:https://zhuanlan.zhihu.com/p/40290931
介绍
Request类是一个http请求的类,对于爬虫而言是一个很重要的类。通常在Spider中创建这样的一个请求,在Downloader中执行这样的一个请求。同时也有一个子类FormRequest继承于它,用于post请求。
在Spider中通常用法: yield scrapy.Request(url = 'zarten.com')
类属性和方法有:
url
method
headers
body
meta
copy()
replace([url, method, headers, body, cookies, meta, encoding, dont_filter, callback, errback])
Request
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags])
参数说明:
- url
请求的url
- callback
回调函数,用于接收请求后的返回信息,若没指定,则默认为parse()函数
- method
http请求的方式,默认为GET请求,一般不需要指定。若需要POST请求,用FormRequest即可
- headers
请求头信息,一般在settings中设置即可,也可在middlewares中设置
- body
str类型,为请求体,一般不需要设置(get和post其实都可以通过body来传递参数,不过一般不用)
- cookies
dict或list类型,请求的cookie
dict方式(name和value的键值对):
cookies = {'name1' : 'value1' , 'name2' : 'value2'}list方式:
cookies = [
{'name': 'Zarten', 'value': 'my name is Zarten', 'domain': 'example.com', 'path': '/currency'}
]
- encoding
请求的编码方式,默认为'utf-8'
- priority
int类型,指定请求的优先级,数字越大优先级越高,可以为负数,默认为0
- dont_filter
默认为False,若设置为True,这次请求将不会过滤(不会加入到去重队列中),可以多次执行相同的请求
- errback
抛出错误的回调函数,错误包括404,超时,DNS错误等,第一个参数为Twisted Failure实例
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import DNSLookupError
from twisted.internet.error import TimeoutError, TCPTimedOutError
class ToScrapeCSSSpider(scrapy.Spider):
name = "toscrape-css"
# start_urls = [
# 'http://quotes.toscrape.com/',
# ]
start_urls = [
"http://www.httpbin.org/", # HTTP 200 expected
"http://www.httpbin.org/status/404", # Not found error
"http://www.httpbin.org/status/500", # server issue
"http://www.httpbin.org:12345/", # non-responding host, timeout expected
"http://www.httphttpbinbin.org/", # DNS error expected
]
def start_requests(self):
for u in self.start_urls:
yield scrapy.Request(u, callback=self.parse_httpbin,
errback=self.errback_httpbin,
dont_filter=True)
def parse_httpbin(self, response):
self.logger.info('Got successful response from {}'.format(response.url))
# do something useful here...
def errback_httpbin(self, failure):
# log all failures
self.logger.info(repr(failure))
# in case you want to do something special for some errors,
# you may need the failure's type:
if failure.check(HttpError):
# these exceptions come from HttpError spider middleware
# you can get the non-200 response
response = failure.value.response
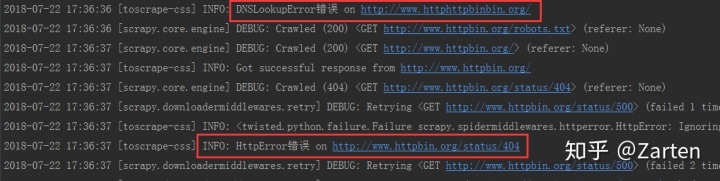
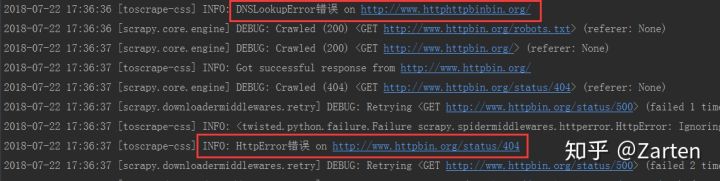
self.logger.info('HttpError错误 on %s', response.url)
elif failure.check(DNSLookupError):
# this is the original request
request = failure.request
self.logger.info('DNSLookupError错误 on %s', request.url)
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.info('TimeoutError错误 on %s', request.url)
- flags
list类型,一般不会用到,发送请求的标志,一般用于日志记录
- meta
可用户自定义从Request到Response传递参数,这个参数一般也可在middlewares中处理
yield scrapy.Request(url = 'zarten.com', meta = {'name' : 'Zarten'})在Response中:
my_name = response.meta['name']不过也有scrapy内置的特殊key,也非常有用,它们如下:
- proxy
设置代理,一般在middlewares中设置
可以设置http或https代理
request.meta['proxy'] = 'https://' + 'ip:port'
- download_timeout
设置请求超时等待时间(秒),通常在settings中设置DOWNLOAD_TIMEOUT,默认是180秒(3分钟)
max_retry_times
最大重试次数(除去第一次下载),默认为2次,通常在settings中 RETRY_TIMES设置
dont_redirect
设为True后,Request将不会重定向
dont_retry
设为True后,对于http链接错误或超时的请求将不再重试请求
handle_httpstatus_list
http返回码200-300之间都是成功的返回,超出这个范围的都是失败返回,scrapy默认是过滤了这些返回,不会接收这些错误的返回进行处理。不过可以自定义处理哪些错误返回:
yield scrapy.Request(url= 'https://httpbin.org/get/zarten', meta= {'handle_httpstatus_list' : [404]})在parse函数中可以看到处理404错误:
def parse(self, response):
print('返回信息为:',response.text)

handle_httpstatus_all
设为True后,Response将接收处理任意状态码的返回信息
dont_merge_cookies
scrapy会自动保存返回的cookies,用于它的下次请求,当我们指定了自定义cookies时,如果我们不需要合并返回的cookies而使用自己指定的cookies,可以设为True
cookiejar
可以在单个spider中追踪多个cookie,它不是粘性的,需要在每次请求时都带上
def start_requests(self):
urls = ['http://quotes.toscrape.com/page/1',
'http://quotes.toscrape.com/page/3',
'http://quotes.toscrape.com/page/5',
]
for i ,url in enumerate(urls):
yield scrapy.Request(url= url, meta= {'cookiejar' : i})
def parse(self, response):
next_page_url = response.css("li.next > a::attr(href)").extract_first()
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url), meta= {'cookiejar' : response.meta['cookiejar']}, callback= self.parse_next)
def parse_next(self, response):
print('cookiejar:', response.meta['cookiejar'])


dont_cache
设为True后,不会缓存
redirect_urls
暂时还不清楚具体的作用,知道的小伙伴们欢迎在评论留言
bindaddress
绑定输出IP
dont_obey_robotstxt
设为True,不遵守robots协议,通常在settings中设置
download_maxsize
设置下载器最大下载的大小(字节),通常在settings中设置DOWNLOAD_MAXSIZE,默认为1073741824 (1024MB=1G),若不设置最大的下载限制,设为0
download_latency
只读属性,获取请求的响应时间(秒)
def start_requests(self):
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
yield scrapy.Request(url= 'https://www.amazon.com', headers= headers)
def parse(self, response):
print('响应时间为:', response.meta['download_latency'])


download_fail_on_dataloss
很少用到,详情看这里
referrer_policy
设置Referrer Policy
FormRequest
FormRequest 类为Request的子类,用于POST请求
这个类新增了一个参数 formdata,其他参数与Request一样,详细可参考上面的讲述
一般用法为:
yield scrapy.FormRequest(url="http://www.example.com/post/action",
formdata={'name': 'Zarten', 'age': '27'},
callback=self.after_post)